 Google’s Gemini line of models has been making waves lately, especially with the new 2.5 Pro model, boasting impressive benchmark scores that have the community buzzing.
Google’s Gemini line of models has been making waves lately, especially with the new 2.5 Pro model, boasting impressive benchmark scores that have the community buzzing.
I’ve been using Gemini models in production for a few months, and I’m calling the bell. Something is going on with these models that the benchmarks don’t show.
Why we bet on Gemini
Before getting into all the details, let me explain a bit about what I’m building and why we bet on Gemini to be our AI partner.
About me: I’m one of the founders of Bidaya AI, we’re aiming to build AI for AEC firms on the business development side, helping them evaluate and submit winning bids.
Our use case tends to be quite document-intensive. We’re often analyzing tons of project documents, and these documents are often filled with images, diagrams, tables, and the occasional poorly scanned document.
As you imagine, I was excited to see how Gemini would perform in our use case as Google was bringing capabilities that no other model could match.
Namely:
- its impressive context window (1M tokens)
- which could help us build strong agents capable of ingesting multiple project documents,
- and its PDF vision
- which could help us extract data we otherwise could miss from PDF text extraction.
It’s also good to note that most of my experience was with Gemini 2.0 Flash and Gemini 2.0 Pro (Experimental), although these issues seem to persist with 2.5.
Initial impressions
On paper, it seemed like our product perfectly matched with Gemini, and our evals corroborated. It did perform well for document analysis.
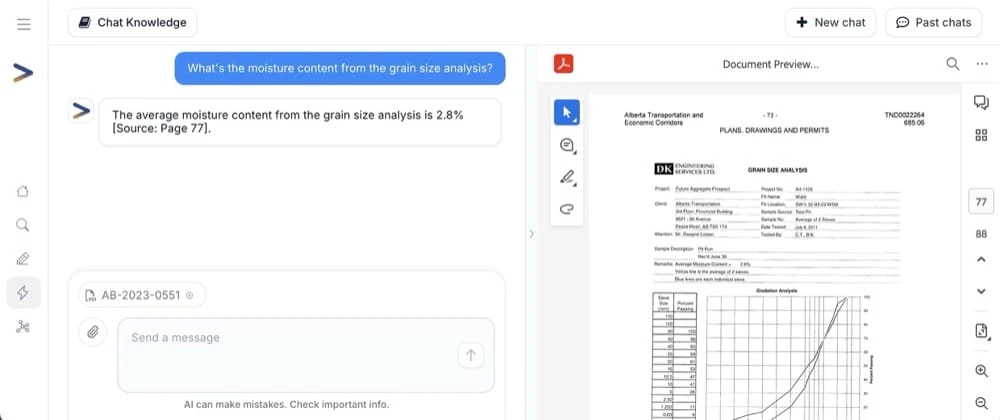
In this example, Gemini was able to find and read data in a scanned report on page 77 of an 88-page document.
At times, however, I’d notice peculiarities.
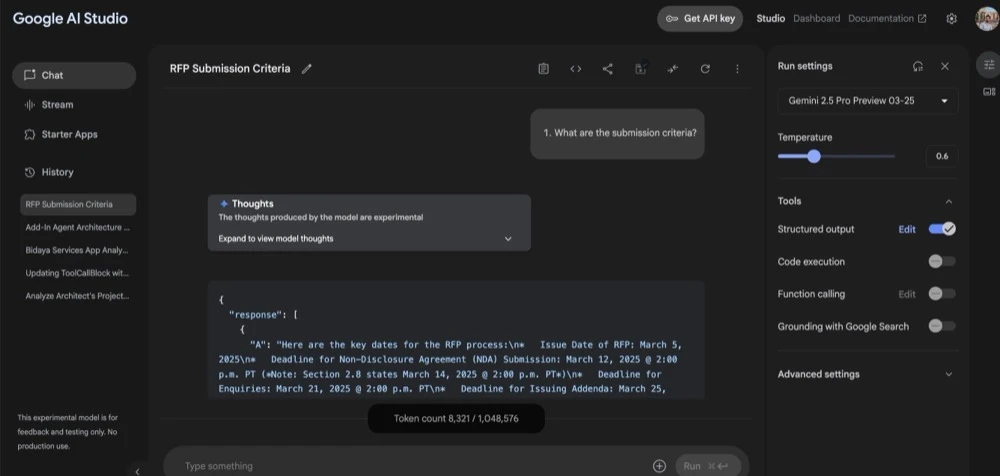
Here, Gemini 2.5 Pro answered a completely different question than what was asked.
Here it just gave back rubbish.
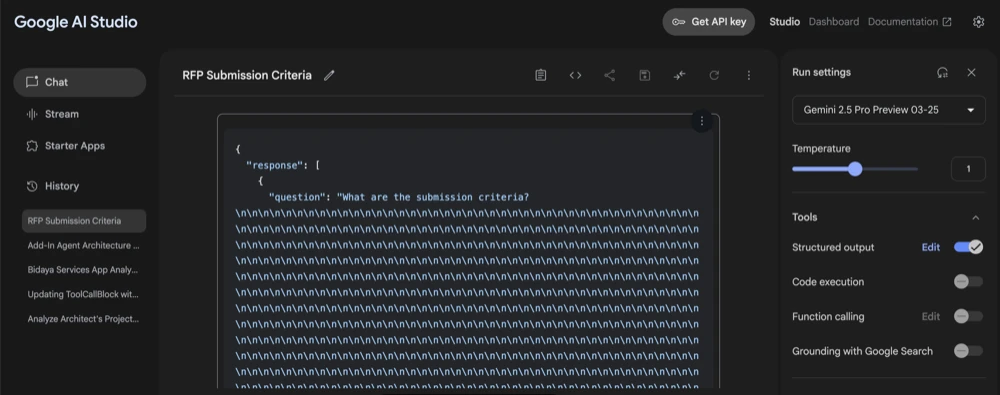
This was a bit puzzling as I wouldn’t expect such elementary issues from a model of this stature.
To be fair, this wasn’t its behaviour most of the time. This would only happen occasionally or on certain days as if it had “bad days”.
I also noticed once it gives a poor response, it would continue to do so for the same type of question. As if there was a caching mechanism it relied on.
But let’s not get bogged down in these anomalies, Gemini Flash and Pro performed well most of the time.
The deal breaker
The real Achilles heel appeared when we tried to build a tool-calling agent using these models. Something really strange happened.
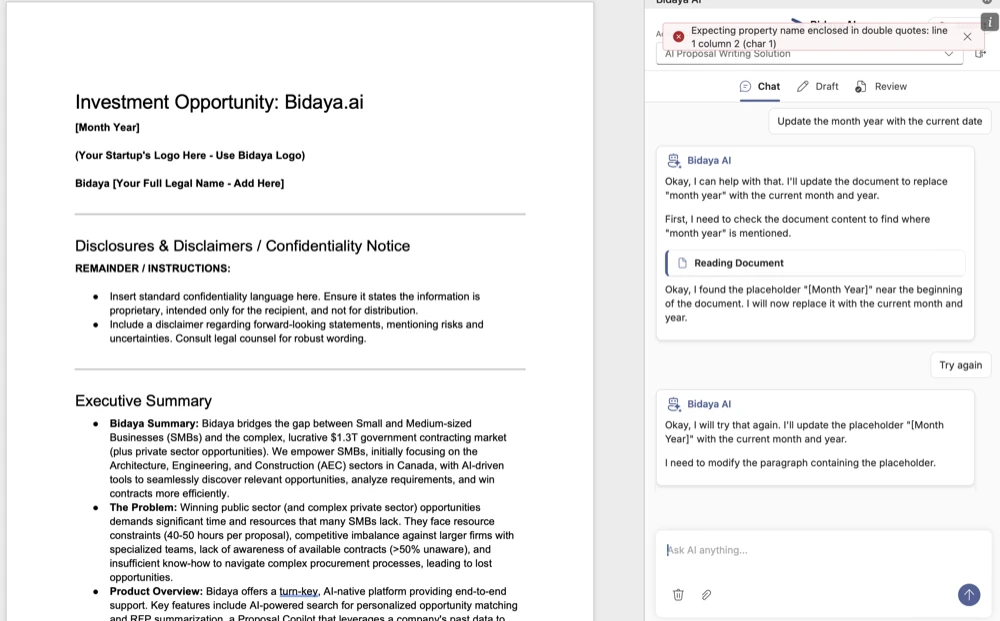
In this example, Gemini mentioned a tool call but didn’t send a signal to invoke it. This was consistent behaviour.
At first, I assumed this was an implementation problem.
My approach to fixing this was two-pronged:
- Prompt engineering
- Tighten the agent code
It felt like fix #1 couldn’t be the solution.
In our examples, it was clear in its responses that Gemini knew it needed to call a tool, it even mentioned the tool name it wanted to call, it just never did.
Nonetheless, I tried what I could:
- Adding more descriptions to each tool definition
- Adding conversation examples with tool calls
- Emphasizing that the AI should call the tools after mentioning them
- Reducing the model temperature
This didn’t help. And examples confused it even more, Gemini actually started writing tool calls within the user response using the same example format I gave. (I didn’t get a chance to screenshot this)
At this point, I was convinced it was a code error. So we go to Fix #2.
Is it a code error?
I read up on Gemini docs and actioned the following:
- Switch to Google’s newest genai SDK (watch for a separate blog article coming on confusion with all the different SDKs for Gemini)
- Use Google’s more reliable AFC (Automatic Function Calling)
- Switch to Google’s Enterprise API, Vertex AI
If it was a logic error that we didn’t call the tool, then these would surely solve it.
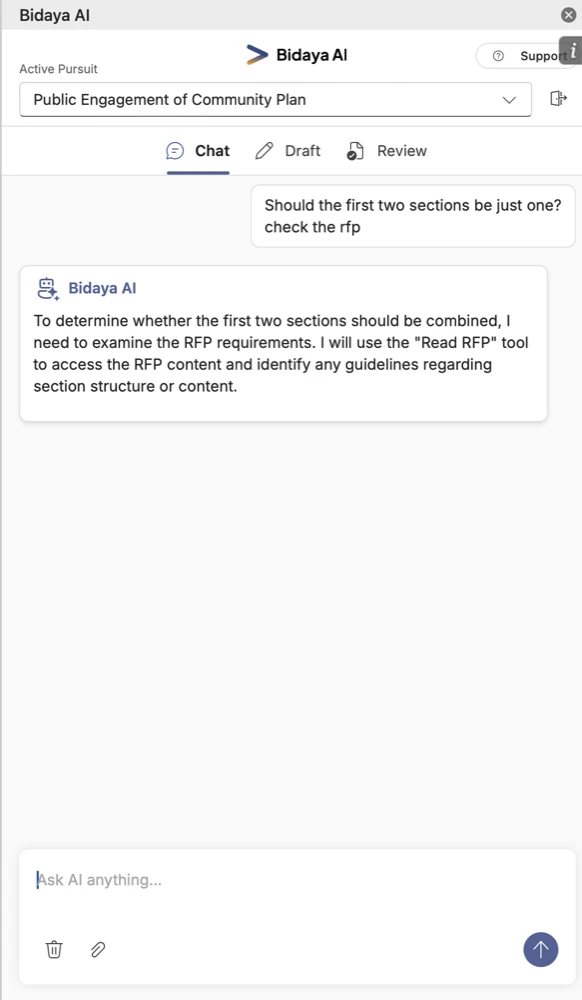
These changes did not solve it.
At this point, it felt like our bet on Gemini was a failed one.
Just to confirm sanity however, I switched back to the OpenAI SDK and used Claude to run our agent and surely enough, it worked.
When we switched back to Gemini on the OpenAI SDK, we had our issue again.
Researching this online, I found a few other developers talking about these issues on various forms, but the community overall was not sounding any major alarms like I’d expect.
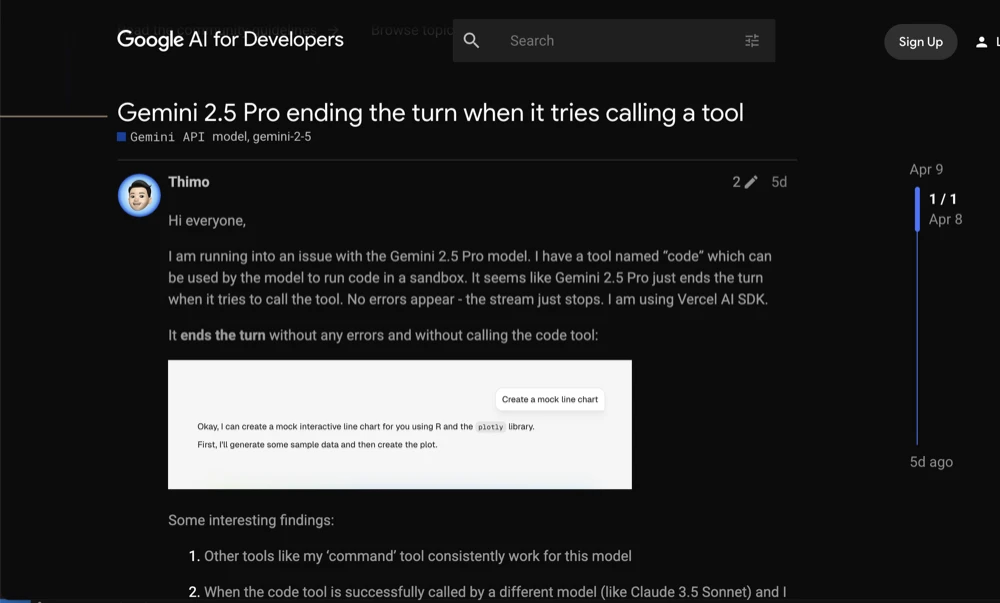 Developers on Google forums with similiar issue
Developers on Google forums with similiar issue
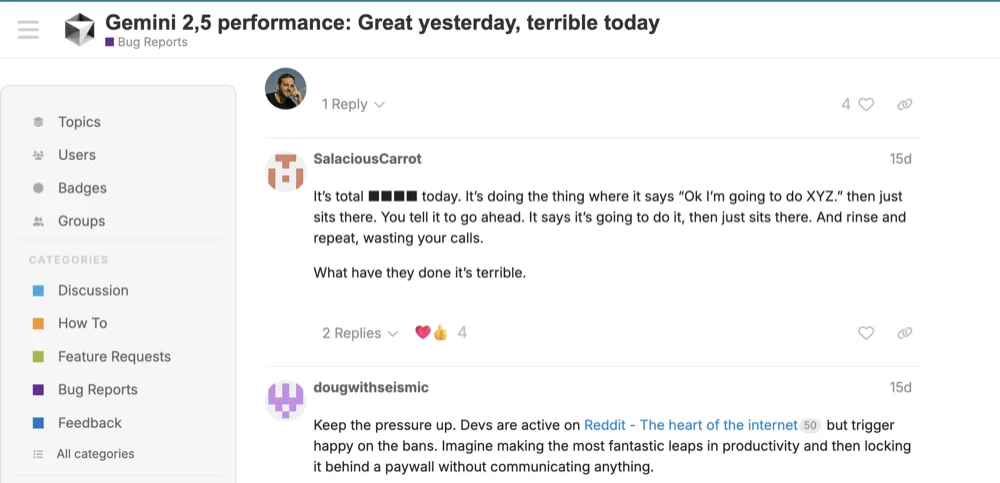 Developers on the Cursor forums with similiar issues
Developers on the Cursor forums with similiar issues
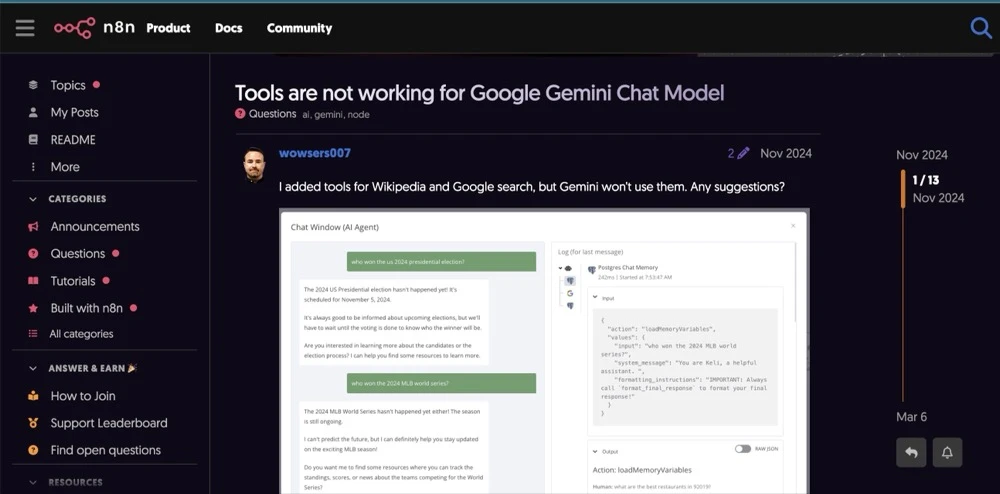 Developers on the n8n forums with similiar issues
Developers on the n8n forums with similiar issues
Even more puzzling despite all these reported issues, is that Gemini still ranks 18 for Tool Calling across all models on the Berkeley benchmark.
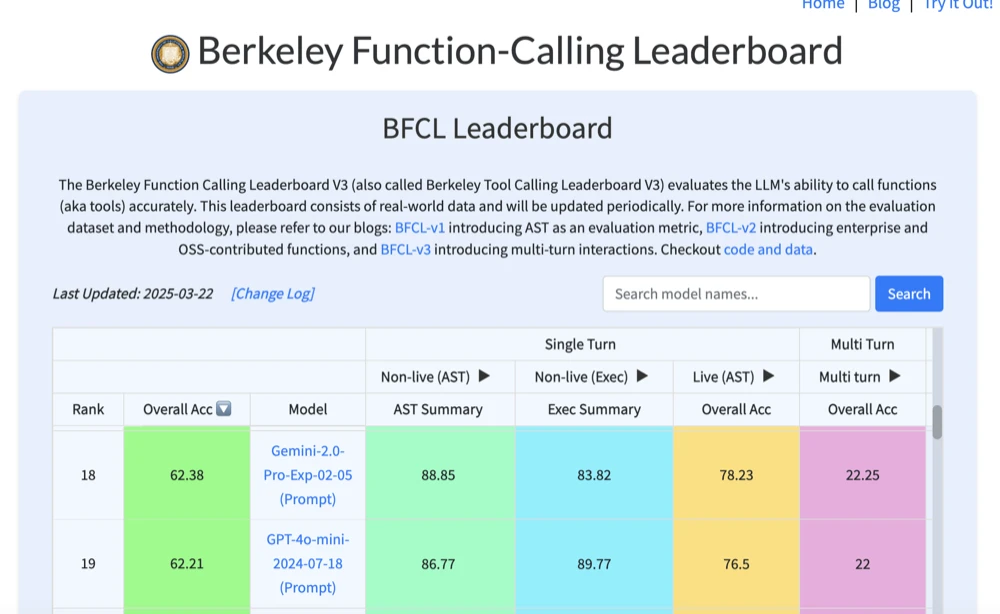
so what’s the deal with Gemini?
Building with LLMs can be frustrating. As a developer, you’re already in a battle to control unusually chaotic systems. With Gemini, this entropy feels much more extreme.
Our production testing revealed a clear pattern:
- Document processing: Strong performance with superior multimodal capabilities
- Tool calling: Persistent failure across SDK variations, regardless of implementation approach
- Inconsistency: Performance varies significantly day-to-day, with entire classes of queries degrading simultaneously
For now, we’ve switched off Gemini for all tool-calling use cases and life is good again.
It feels like there’s something painfully obvious Google is missing with these models.
We still use Gemini for document processing where it performs well and we’ll continue monitoring how 2.5 Pro performs but we’re not holding our breath.
What has your experience been with Gemini in production? Have you found solutions to these tool-calling issues that we missed? I added comments to this article to discuss.